 【盘中宝•数据】GPT模型迭代伴随着数据量爆炸式增长,相关上市公司数据量指标一览(附表)
【盘中宝•数据】GPT模型迭代伴随着数据量爆炸式增长,相关上市公司数据量指标一览(附表)
算法、算力、数据是人工智能核心的三大要素,三要素不断创新推动人工智能行业发展。数据方面,不同场景和需求推动数据规模快速扩大,多个知识集的建立推动人工智能应用落地。同时高算力也意味着会产生更多数据量。近年来全球数据量呈井喷式发展。根据IDC发布的《DataAge2025》报告预测,全球每年产生的数据将从2018年的33ZB增长到2025年的175ZB。根据中国信通院测算,2017年到2021年我国数据量从2.3ZB增长至6.6ZB,全球占比9.9%,仅次于美国,位居世界第二。
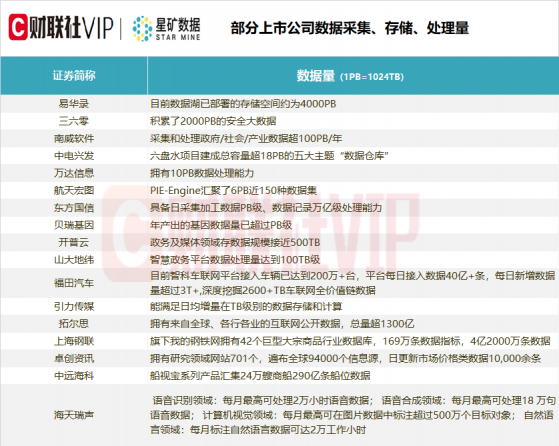
申港证券曹旭特研报指出,GPT模型的每次迭代都伴随着参数数量和预训练数据量的爆炸式增长,目前研究证明了随着增加训练数据量,预训练模型在各种下游任务中效果越好,预计产业下游对数据的数量和质量需求同步增加,利好产业中游数据服务中的采集、加工、分析、存储等环节。据财联社不完全统计,相关上市公司数据采集、存储、处理量如下:
【盘中宝•数据】GPT模型迭代伴随着数据量爆炸式增长,相关上市公司数据量指标一览(附表)